# yolo to json.py
import os
import json
import glob
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[2])/2.0
y = (box[1] + box[3])/2.0
w = abs(box[2] - box[0])
h = abs(box[3] - box[1])
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return [x,y,w,h]
def convert_annotation(json_path, output_path):
with open(json_path, 'r') as json_file:
data = json.load(json_file)
image_name = os.path.splitext(data['META']['Image File Name'])[0]
width = data['META']['Image Width MAGNITUDE'] # 이미지 넓이 키값 위치 지정
height = data['META']['Image Height MAGNITUDE'] # 이미지 높이 키값 위치 지정
try :
annotations = data['ANNOTATION']['Anntation Regions'] # ANNOTATION 키 값이 'Anntation Regions'일 경우(제공된 데이터 내 오타 존재 때문)
except KeyError:
annotations = data['ANNOTATION']['Annotation Regions'] # ANNOTATION 키 값이 'Annotation Regions'일 경우
with open(os.path.join(output_path, f'{image_name}.txt'), 'w') as outfile:
for annotation in annotations:
category_id = 0
x_coordinates = annotation['Polygon X Coordinate']
y_coordinates = annotation['Polygon Y Coordinate']
bbox = [min(x_coordinates), min(y_coordinates), max(x_coordinates), max(y_coordinates)]
bb = convert((width,height), bbox)
if any([coord > 1 or coord < 0 for coord in bb]):
print(f"이상한 좌표값 발견: {bb}, 파일: {json_path}")
outfile.write(f"{category_id} {bb[0]} {bb[1]} {bb[2]} {bb[3]}\n")
# json 파일 위치 경로 입력
json_paths = glob.glob('C:/Users/User/Desktop/InsectData/Data/Training/labelData/TL1/PtecticusTenebrifer/Caterpillar/Cam2/*.json')
# 저장될 위치 경로 입력
output_path = 'C:/Users/User/Desktop/InsectData/ConvertData/Cam2'
os.makedirs(output_path, exist_ok=True)
for json_path in json_paths:
convert_annotation(json_path, output_path)
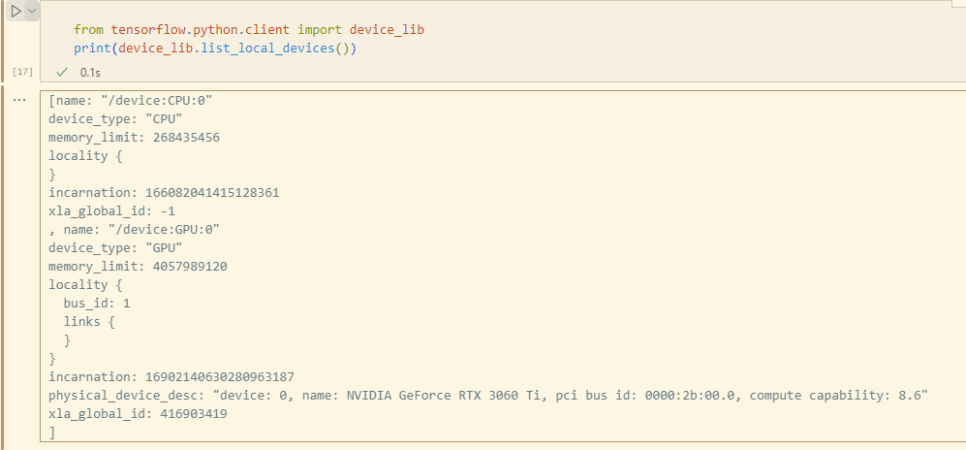 from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
GPU 를 잡아주는지 확인 후
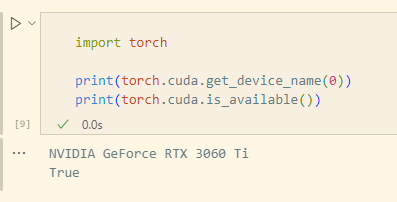
import torch
print(torch.cuda.get_device_name(0))
print(torch.cuda.is_available())
위 명령어를 실행하면
본인의 디바이스 이름과 CUDA와 호환되는 여부를 True 로 반환해준다
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
GPU 를 잡아주는지 확인 후
import torch
print(torch.cuda.get_device_name(0))
print(torch.cuda.is_available())
위 명령어를 실행하면
본인의 디바이스 이름과 CUDA와 호환되는 여부를 True 로 반환해준다
 만일 torch.cuda.is_available() 이 False 로 반환된다면
어딘가 잘못된 것이니 다시 잡아주어야 하며,
이 과정에서 NVIDIA 그래픽 드라이버 여부,
CUDA 와 cuDNN 버전 호환 여부 등
여러가지 확인을 해보아야 한다
2. YOLO v8 설치
이어서 yolo v8 로 학습을 위한 환경 세팅을 진행한다
yolo 설치에는 두가지 방식이 있다
1) git clone 을 활용하여 github 의 파일을 가져오기
2) pip install
필자는 pip install 을 활용했으며
그와 같은 방법을 안내한다
conda 를 활용해 가상환경을 만들었으며
Python 3.9 버전을 활용했다
(conda 가상환경)pip install ultralytics
위 명령어로 yolo v8 설치를 하면
(conda 가상환경)pip list
# 혹은 아래 경로
C:\Users\User\anaconda3\envs\가상환경명\Lib\site-packages\ultralytics
에 설치된 것을 확인할 수 있다
3. bbox labeling
yolo 학습을 위해선 yolo 에 맞게
데이터를 구성해 주어야 한다
yolo 는 bbox 라 해서 Bounding Box
즉, 네모난 박스로 label 처리를 한 객체의 좌표가 필요하다
이 데이터는
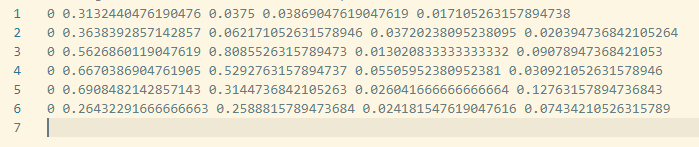
0 0.3132440476190476 0.0375 0.03869047619047619 0.017105263157894738
이런 형태로 된 txt 파일인데
어디서 라벨링을 어떻게 하느냐에 따라 달라질 수 있다
띄어쓰기를 기준으로
처음 0 : 클래스 넘버
두번째 : bbox 의 가운데 x좌표
세번째 : bbox 의 가운데 y좌표
네번째 : bbox 의 넓이
다섯번째 : bbox 의 높이
위와 같이 구성이 되어 있다
필자는 현재 진행중인 프로젝트의 내용에 따라
AI hub 에 제공되어 있는 데이터를 받아서 활용중이다
다만 AI hub 에 제공되어 있는 데이터는
모두 json 형태였으며, bbox가 아닌 polygon 형태로
라벨링을 진행한 데이터였다
json 파일 안에 polygon 데이터가 있고
이 polygon 데이터의 좌표의 x값의 최소, 최대
y값의 최소, 최대를 구하면 bbox 를 구할 수 있을 것 같아
수천개의 데이터를 정제할 수 있게 코드를 구성했다
만일 torch.cuda.is_available() 이 False 로 반환된다면
어딘가 잘못된 것이니 다시 잡아주어야 하며,
이 과정에서 NVIDIA 그래픽 드라이버 여부,
CUDA 와 cuDNN 버전 호환 여부 등
여러가지 확인을 해보아야 한다
2. YOLO v8 설치
이어서 yolo v8 로 학습을 위한 환경 세팅을 진행한다
yolo 설치에는 두가지 방식이 있다
1) git clone 을 활용하여 github 의 파일을 가져오기
2) pip install
필자는 pip install 을 활용했으며
그와 같은 방법을 안내한다
conda 를 활용해 가상환경을 만들었으며
Python 3.9 버전을 활용했다
(conda 가상환경)pip install ultralytics
위 명령어로 yolo v8 설치를 하면
(conda 가상환경)pip list
# 혹은 아래 경로
C:\Users\User\anaconda3\envs\가상환경명\Lib\site-packages\ultralytics
에 설치된 것을 확인할 수 있다
3. bbox labeling
yolo 학습을 위해선 yolo 에 맞게
데이터를 구성해 주어야 한다
yolo 는 bbox 라 해서 Bounding Box
즉, 네모난 박스로 label 처리를 한 객체의 좌표가 필요하다
이 데이터는
0 0.3132440476190476 0.0375 0.03869047619047619 0.017105263157894738
이런 형태로 된 txt 파일인데
어디서 라벨링을 어떻게 하느냐에 따라 달라질 수 있다
띄어쓰기를 기준으로
처음 0 : 클래스 넘버
두번째 : bbox 의 가운데 x좌표
세번째 : bbox 의 가운데 y좌표
네번째 : bbox 의 넓이
다섯번째 : bbox 의 높이
위와 같이 구성이 되어 있다
필자는 현재 진행중인 프로젝트의 내용에 따라
AI hub 에 제공되어 있는 데이터를 받아서 활용중이다
다만 AI hub 에 제공되어 있는 데이터는
모두 json 형태였으며, bbox가 아닌 polygon 형태로
라벨링을 진행한 데이터였다
json 파일 안에 polygon 데이터가 있고
이 polygon 데이터의 좌표의 x값의 최소, 최대
y값의 최소, 최대를 구하면 bbox 를 구할 수 있을 것 같아
수천개의 데이터를 정제할 수 있게 코드를 구성했다
 단일 객체이기 때문에 클래스는 모두 0이고
각 객체들이 위치하고 있는 bbox를 뽑아내어
txt 파일로 만든 파일이다
이 라벨링 과정은 ROBOFLOW 라는것을 통해 쉽게 할 수 있다 하지만
해당 사이트에서는 장수에 제한을 두고 있기 때문에
직접 정제하고 싶어 이런식으로 진행했다
(데이터가 수만장이기 때문도 있음)
단일 객체이기 때문에 클래스는 모두 0이고
각 객체들이 위치하고 있는 bbox를 뽑아내어
txt 파일로 만든 파일이다
이 라벨링 과정은 ROBOFLOW 라는것을 통해 쉽게 할 수 있다 하지만
해당 사이트에서는 장수에 제한을 두고 있기 때문에
직접 정제하고 싶어 이런식으로 진행했다
(데이터가 수만장이기 때문도 있음)
 이렇게 학습을 마치면
이렇게 학습을 마치면
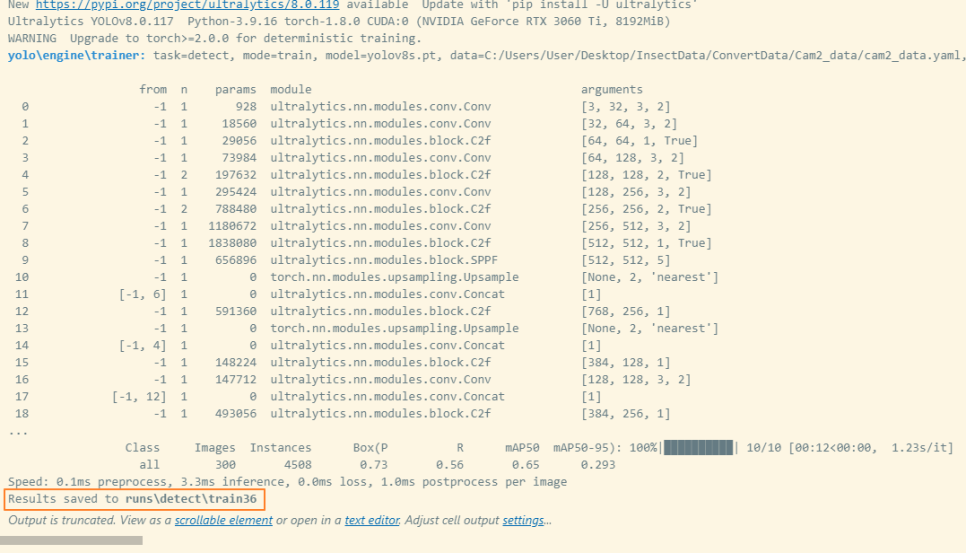 그 결과가 어디에 저장되었는지 알려주는데
라이브러리가 설치된 ultralytics 폴더 안에
혹은 test를 진행한 파일이 위치한 폴더 안에
runs / detect / train(번호)
로 위치하게 된다
해당 위치로 가보면
그 결과가 어디에 저장되었는지 알려주는데
라이브러리가 설치된 ultralytics 폴더 안에
혹은 test를 진행한 파일이 위치한 폴더 안에
runs / detect / train(번호)
로 위치하게 된다
해당 위치로 가보면
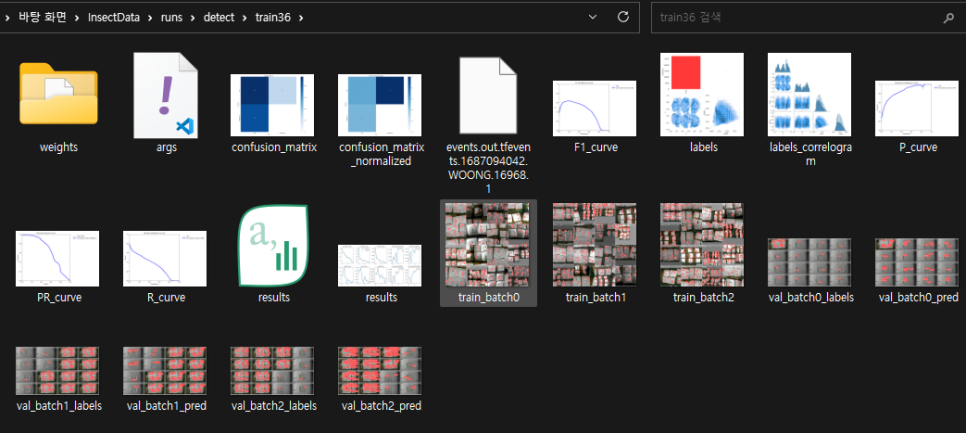 이런식으로 결과가 어떻게 되었는지
알려주는 모습들을 볼 수 있다
그리고 weights 폴더 안의 best.pt 를 통해
predict 까지 진행할 수 있다
이런식으로 결과가 어떻게 되었는지
알려주는 모습들을 볼 수 있다
그리고 weights 폴더 안의 best.pt 를 통해
predict 까지 진행할 수 있다
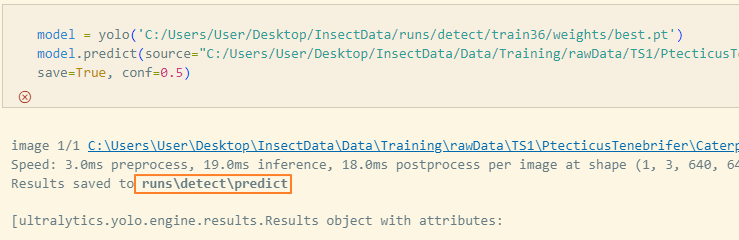 이렇게 어떤 폴더에 저장됐는지까지 알려준다
가서 확인해보면
이렇게 어떤 폴더에 저장됐는지까지 알려준다
가서 확인해보면
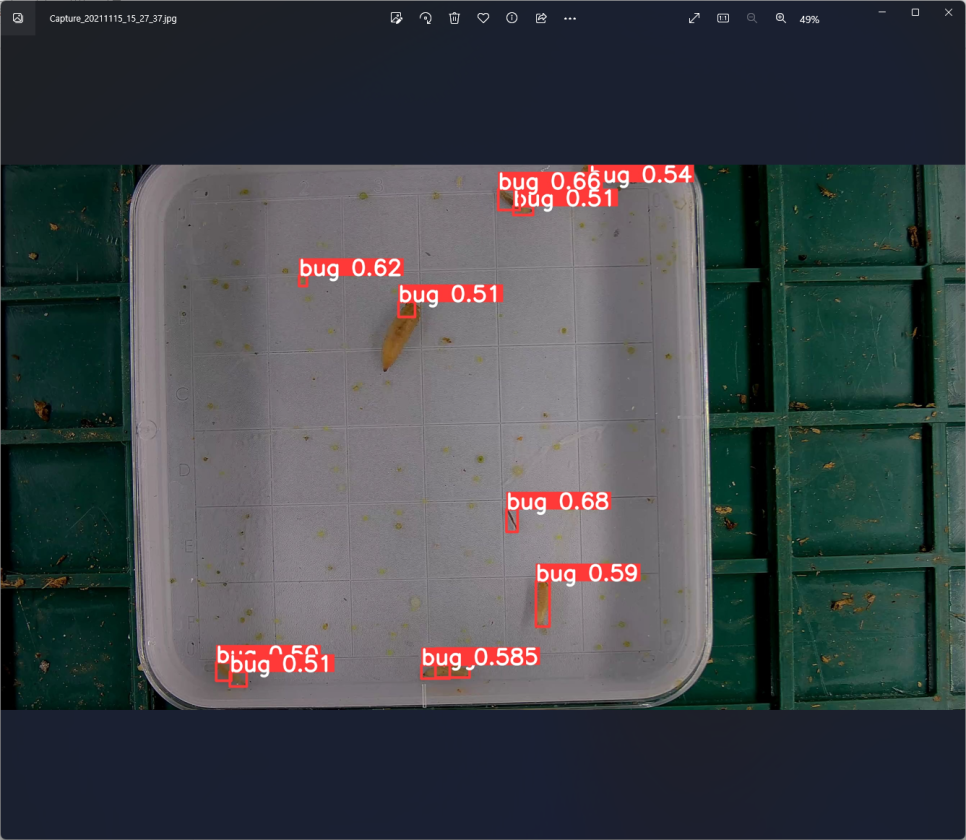 이렇게 인식을 시도한 그림을
확인할 수 있다
데이터도 많고 시간이 좀 걸릴듯 하여
epochs 를 10밖에 안주었더니
어느정도밖에 인식을 하지 못한다
추후 더 시간을 들여 학습을 시키고
프로젝트에 적용시키도록 할 예정이다
이렇게 인식을 시도한 그림을
확인할 수 있다
데이터도 많고 시간이 좀 걸릴듯 하여
epochs 를 10밖에 안주었더니
어느정도밖에 인식을 하지 못한다
추후 더 시간을 들여 학습을 시키고
프로젝트에 적용시키도록 할 예정이다